최근 인공지능(AI)이 우리의 일상생활에서 점점 더 중요한 역할을 차지하고 있습니다. 그 중에서도 AI 기반의 상품추천 시스템은 온라인 쇼핑 시장에서 상품을 찾고 구매하는 과정을 더욱 효율적이고 개인화된 경험으로 만들어 주는 역할을 합니다. 이 글에서는 OpenAI 임베딩을 활용한 상품추천 시스템 구현에 대해 설명하고자 합니다.
목차
- OpenAI 임베딩의 이해
- 상품추천 시스템 구현 방법
- 데이터수집 전처리
- 상품추천 실습 스펙
- 실습순서
OpenAI 임베딩의 이해
임베딩이란?
임베딩이란 벡터 공간에 표현되는 객체 간의 관계를 나타내는 기술입니다. 객체는 단어, 문장, 이미지 등 다양한 형태일 수 있으며, 이러한 객체들을 벡터로 변환하는 과정을 임베딩이라고 합니다. 임베딩을 통해 고차원의 데이터를 저차원의 벡터로 변환함으로써, 계산량을 줄이고 효율적인 분석이 가능합니다.
OpenAI 임베딩의 특징
OpenAI는 GPT와 같은 대형 언어 모델을 통해 텍스트 데이터를 다루는 데 최적화된 임베딩을 제공합니다. 이를 통해 상품명, 상품설명 등 텍스트 데이터를 고품질의 벡터로 변환하여 상품추천 시스템에서 활용할 수 있습니다.
상품추천 시스템 구현 방법
데이터 수집 및 전처리
상품추천 시스템 구현을 위해 먼저 상품 데이터와 고객의 상호작용 데이터를 수집해야 합니다. 상품 데이터는 상품명, 카테고리, 상품설명 등의 정보가 포함됩니다. 상호작용 데이터는 구매 내역, 상품 클릭, 검색 기록 등 고객의 행동 패턴을 나타냅니다. 수집된 데이터는 전처리 과정을 거쳐 정제된 형태로 변환합니다.
상품 추천 실습 스펙
- 사용언어 : python 3.10.2
- 라이브러리 : OpenAI / pandas / numpy
실습순서
- 임베딩 데이터 전처리 - 임베딩에 활용할 데이터 수집 및 데이터 저장
- 임베딩 벡터 추출(OpenAI embedding)
- 코사인 유사도 함수 적용
임베딩 데이터 전처리
제가 구현하려는건 쇼핑몰에 적용 가능항 상품 추천 시스템입니다. 그래서 임의에 쇼핑몰을 하나 정해서 엑셀로 데이터를 정리 했습니다. 데이터 수집은 수동으로 10개정도를 모았고 서로 다른 카테고리, 서로 다른 브랜드, 다른 재질의 상품 데이터를 수집했습니다.
수집된 데이터중 브랜드명, 카테고리, 상품명, 재질정보, 가격등을 하나로 합쳐 별도의 필드에 모아주었습니다.
우선 수집된 엑셀 데이터를 DB 에 입력하는것 부터 시작하겠습니다.
FastAPI 를 활용해서 로컬에 저장된 데이터를 읽어 들이고, 읽어온 데이터를 미리 생성한 데이터베이스에 저장하도록 했습니다.
이때 저장하는 데이터의 제일 첫번째에 summary 라는 모든 텍스트 정보의 집합 텍스트가 위치해 있습니다.
엑셀파일을 읽어들이는데는 pandas 의 read_excel 를 사용했습니다. 읽어들이는 파일이 csv 일 경우에는 read_csv 함수를 사용하세요
pandas 를 사용하려면 "pip install pandas" 하고 "import pandas as pd" 로 import 해주세요
pip install pandas
import pandas as pd
임베딩 벡터 추출(OpenAI embedding)
테이블에 저장된 데이터중 summary 값만 가져다가 OpenAI 의 Embedding 기능을 활용해 벡터값을 구하세요

읽어온 summary 를 위의 text 값에 넣어서 벡터 값을 구해올수 있습니다.
구해온 벡터 값은 다시 DB 에 저장해야하는데요 이때 일반 텍스트 값으로 저장하려고하면 오류가 발생할수 있습니다. OpenAI 가 준 벡터 값자체가 리스트 형태로 되어 있다보니 사이즈도 커다란데요 그래서 저장할때는 bytes 로 변환해서 저장해야합니다.

위의 코드에서 get_embedding에 들어가는 두개의 값은 아래와 같습니다
- summary = DB 에 저장되어 있던 상품 요약정보의 총합
- openai_embedding_model = "text-embedding-ada-002"
벡터로 변환된 값을 openai_embeddings 에 담고 이 값을 다시 "np.array(openai_embeddings).tobytes()" 이런식으로 바이트로 변환해서 테이블에 다시 저장했습니다. 이때 NumPy 배열인 openai_embeddings를 bytes 형식으로 인코딩해주어야 하는데 이 코드를 실행하면 openai_embeddings 배열의 모든 요소가 바이트로 변환되어 하나의 이진 데이터로 합쳐집니다. 이진 데이터는 네트워크 전송 또는 파일 저장과 같은 작업에서 사용할 수 있습니다.
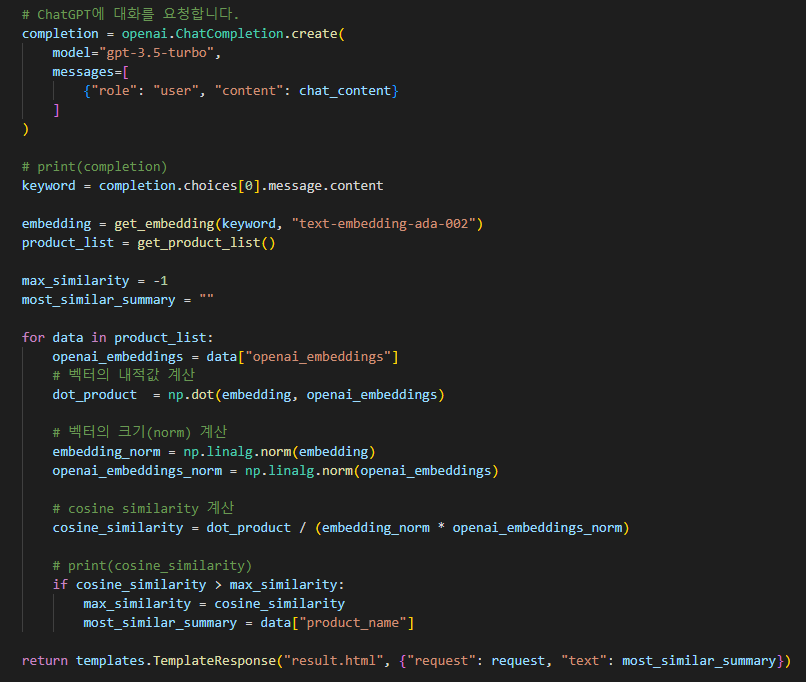
이렇게 저장된 데이터를 가지고 코사인 계산을 통해서 유사도를 구해보도록 하겠습니다.
임베딩에서 코사인 유사도란 벡터 공간에서 두 벡터 간의 코사인 각도를 사용하여 유사성을 측정하는 방법을 의미합니다. 코사인 유사도는 -1에서 1 사이의 값을 가지며, 값이 1에 가까울수록 두 벡터가 유사하다고 판단할 수 있습니다. 상품추천 시스템에서 임베딩을 활용한 코사인 유사도는 상품 간의 유사성을 평가하는 데 사용됩니다. 이를 통해 고객에게 비슷한 상품을 추천하는 것이 가능해집니다.
코사인 유사도 함수 적용
- 사용자가 입력한 데이터에서 키워드를 추출합니다. 이때 chatGPT 의 API 를 활용해 질의해서 키워드만 추출합니다.
- 추출한 데이터를 OpenAI 임베딩을 통해 벡터값을 구합니다.
- 사용자가 입력한 벡터 값과 기존에 입력된 벡터 값의 코사인 유사도를 측정해서 가장 1에 근접한 데이터를 선정합니다.
결론
OpenAI 임베딩을 활용한 상품추천 시스템은 온라인 쇼핑 시장에서 고객들에게 개인화된 쇼핑 경험을 제공하는 데 큰 역할을 합니다. 상품 데이터와 고객의 상호작용 데이터를 바탕으로 모델을 학습시키고, 이를 평가하여 최적의 상품추천 시스템을 구축할 수 있습니다. 이를 통해 고객 만족도를 높이고, 온라인 쇼핑 시장에서의 경쟁력을 강화할 수 있는데요. 이를 위해서는 임베딩뿐만아니라 고객의 상호작용 데이터를 기반으로 학습시키는 파인튜닝등의 활용도필요한점을 잊으면 안됩니다.
'IT정보 > OpenAI API' 카테고리의 다른 글
| 'Auto-GPT' 초간단 설치방법 (0) | 2023.05.03 |
|---|

댓글